CSAPP第五章的读书笔记。
5.2 表示程序性能
引入度量程序性能的指标:每元素的周期数(CPE,Cycles Per Element)。通常使用时钟周期作为过程执行的长度的度量单位。
许多过程含有在一组元素上迭代的循环,设被处理元素个数为 $n$,此时过程执行时间和 $n$ 近似成线性关系 $kn + b$。此时称线性因子 $k$ 为 CPE 的有效值。当 $n$ 较大时,过程的运行时间就会主要由 $k$ 决定。
我们的关注重点在于给定的向量长度而不是循环次数,因为循环次数可以采用诸如循环展开之类的技巧进行优化。因此,我们的关注点为每元素的周期数而非每次循环的周期数。
${\bf N{\scriptsize OTE}}.$ 这个概念和算法的时间复杂度无关,因为 CPE 关注的是过程在给定的向量长度上的执行性能。
练习题 5.2
绘制图像得:
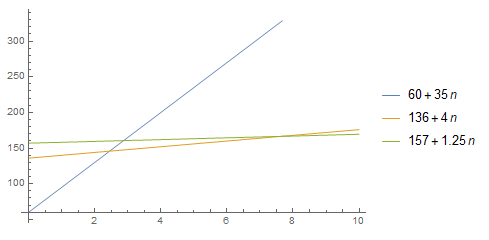
易得:
- 当 $x \in [0..2]$ 时,$60 + 35n$ 最快;
- 当 $x \in [3..7]$ 时,$136 + 4n$ 最快;
- 当 $x \geq 8$ 时,$157 + 1.25n$ 最快。
5.4 消除循环的低效率
代码移动(code motion)是一个常见的优化例子,它识别要重复执行多次(例如在循环内)但结果不会改变的计算,并将其移动至该重复进行的过程之前。
例子:对长度为 $n$ 的字符串 s 而言,以下代码执行的时间复杂度是 $O(n^2)$:
| |
通过将 strlen 函数移动至循环之前,可以将这一过程的时间复杂度优化到 $O(n)$:
| |
练习题 5.3
| 代码 | min | max | incr | square |
|---|---|---|---|---|
| A. | 1 | 91 | 90 | 90 |
| B. | 91 | 1 | 90 | 90 |
| C. | 1 | 1 | 90 | 90 |
5.5 减少过程调用
循环内的过程调用会增加开销。如果能将减少循环中的函数调用,会对提升性能有所帮助。
以边界检查为例,数组访问时进行边界检查将会很大程度上损害程序的性能。但是,在处理器分支预测的帮助下,边界检查造成的性能影响有可能被克服:在 combine3 函数中,从循环中去除了 get_vec_element 函数后,程序并未产生明显的性能提升;这是因为在这段程序中,不可能产生数组越界问题,因此 get_vec_element 总是确定索引在界内,因此这个过程是高度可预测的。
${\bf N{\scriptsize OTE}}.$ 书中实例代码的安全性问题:
在
combine3之前的版本,循环过程是按如下方式进行的:
1 2 3 4 5for(i = 0; i < length; i++) { data_t val; get_vec_element(v, i, &val); *dest = *dest OP val; }可以看到
get_vec_element的返回值并没有被使用,边界检查对运算结果造成的唯一影响就是在索引越界时,val将不会被赋值。然而,这一点是危险的,因为val并没有被赋初值:这意味着一个随机的垃圾值将参与运算,同样引发了 UB 行为。多余的边界检查在影响性能的同时,反倒造成了更大的不安全性。
5.6 消除不必要的内存引用
寄存器的读写速度远快于内存,如果能将重复的大量内存读写改为读写寄存器,将能有效提升程序性能。例如,示例代码在每次循环中都直接使用 dest 参与运算,导致每次循环都需要进行一次多余的内存 R/W 操作;如果用一个中间变量 acc 代替 dest 参与运算,仅在循环结束后将运算结果写入 dest, 性能将产生十分显著的提高。
很多情况下,由于内存别名的因素,编译器不能把内存引用转化为等价的寄存器调用。如,考虑如下例子:
考虑 data_t 为 long, OP 为 *,IDENT 为 1,对 v = $[2,3,5]$ 按如下方式分别进行调用:
| |
由于 combine3 每次运算时都将结果写入 v[2],会造成这样的行为差异:
| 函数 | 初始值 | 循环之前 | i = 0 | i = 1 | i = 2 | 最后 |
|---|---|---|---|---|---|---|
combine3 | $[2,3,5]$ | $[2,3,1]$ | $[2,3,2]$ | $[2,3,6]$ | $[2,3,36]$ | $[2,3,36]$ |
combine4 | $[2,3,5]$ | $[2,3,5]$ | $[2,3,5]$ | $[2,3,5]$ | $[2,3,5]$ | $[2,3,30]$ |
由于事先无法判断函数会在哪里被调用以及程序员设计的真实意图,在比较保守的优化级别(如 -O1 )下,combine3 中的内存引用不会被优化。